IA, ChatGPT : Quel avenir pour la vie privée ?

Au milieu de la montée en puissance des IA, le sujet de la vie privée est plus pertinent que jamais. Les algorithmes et les intelligences artificielles jouent un rôle de plus en plus important dans notre vie quotidienne, offrant une aide précieuse pour des tâches allant de la reconnaissance vocale à la génération de contenu.
Mais à mesure que nous dépendons de plus en plus de ces technologies, nous nous posons des questions sur leur impact sur notre vie privée et la manière dont elles utilisent et protègent nos données personnelles. Dans ce contexte, examinons le devenir de la vie privée si l’IA s’en mêle.
L’intelligence artificielle en question
ChatGPT est un modèle développé par OpenAI, sa formation initiale a commencé en 2019 et sa première publication remonte à 2020. OpenAI continue de développer et de mettre à jour son modèle pour améliorer ses performances. OpenAI est capable de générer du texte en se basant sur des connaissances textuelles antérieures à 2022 et accède à internet en temps réel.
Au moment ou je rédige cet article, ChatGPT est capable de produire un texte à consonance humaine remarquable. Il peut également générer des réponses créatives assez bluffantes. Les progrès de l’IA sont exponentiels. La génération actuelle de chatbots aurait déjà dépassé le test de Turing.
Le test de Turing est un test de reconnaissance de l’intelligence conçu par le mathématicien et informaticien britannique Alan Turing en 1950. Il se compose d’une conversation à travers un canal de communication, où un humain juge si le correspondant est un autre humain ou une machine. Si le juge ne peut pas déterminer avec certitude si le correspondant est une machine, la machine est considérée comme ayant réussi le test et avoir une intelligence artificielle capable de se faire passer pour un humain. Le test de Turing est perçu comme un élément fondamental dans l’histoire de l’IA et continue d’être un sujet de débat.
ChatGPT nous explique pourquoi :
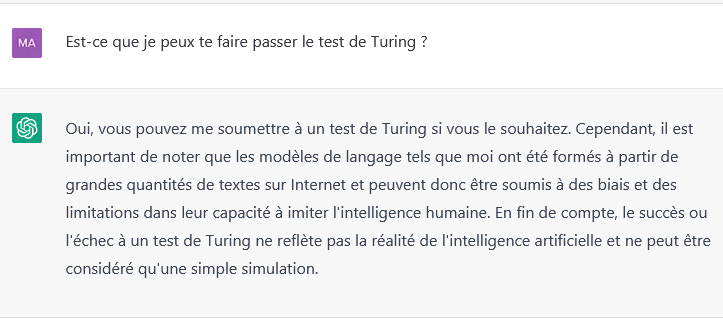
Capture d’écran d’une conversation avec ChatGPT – ©VPNMonAmi
A terme, les chatbots alimentés par l’intelligence artificielle seront bientôt appliqués à toutes sortes d’emplois et de tâches. Ce n’est qu’une question de temps avant que l’interaction avec l’IA ne fasse partie intégrante de notre quotidien. Cette prolifération ne fera qu’accélérer encore plus son développement.
Nous avons remarqué que malgré tout le tapage médiatique fait autour de ChatGPT, les questions de confidentialité soulevées par l’IA ont été assez peu abordées. Et pourtant, sans données, il n’y aurait pas d’IA.
Entrainer une IA nécessite beaucoup de données et beaucoup d’humains
Eh oui, car il s’agit bien d’un entrainement.
On dit qu’on entraîne une intelligence artificielle car cela consiste à lui fournir de beaucoup de données pour qu’elle puisse apprendre à effectuer des tâches spécifiques de manière autonome. Lors de cet entraînement, l’IA est capable de tirer des conclusions à partir des données qu’elle reçoit et de les utiliser pour améliorer ses performances. Cette forme d’apprentissage automatique passe par une préparation méthodique en amont pour permettre à l’IA de s’adapter dans le temps.
Des quantités massives de données sont donc nécessaires pour former la plupart des modèles d’Intelligence Artificielle. En effet, plus l’IA reçoit d’informations à traiter, plus elle est capable de détecter des modèles, d’anticiper et de créer quelque chose d’entièrement nouveau.
Une purge des informations est obligatoire
Avant qu’une Intelligence Artificielle puisse être entraînée sur des données, celles-ci doivent être nettoyées, ce qui signifie les formater correctement et créer une modération (dans quelle mesure, ça on ne sait pas). A noter qu’OpenAI a fait appel à des centaines de personnes au Kenya pour nettoyer les données de GPT-3, certains déclarent avoir été traumatisés par ce travail tant la nature des informations à trier pouvaient être choquantes, nuisibles, violentes ou gores.

Auto, l’IA du vaisseau Axiom, est le principal antagoniste du film d’animation des Studios Pixar de Disney, WALL·E, sorti en 2008.
Par ailleurs, nous n’avons aucun moyen de savoir si certaines informations fournis à l’IA, dans le cadre de son entrainement, ont été altérées ou tout simplement exclues du modèle.
Afin que vous vous rendiez compte de ce que cela représente, dites-vous que l’intégralité de Wikipédia en anglais, qui comprend environ 6 millions d’articles, n’a constitué que 0,6 % des données d’entraînement de GPT-3. ChatGPT n’est qu’une variante.
L’IA a ses limites
Une IA entraînée sur des données n’apprendra à gérer des situations que grâce à l’ensemble des éléments dont elle dispose. Si vos données ne sont pas représentatives, l’IA créera des biais dans ses prises de décision.
A titre d’exemple, en 2018, Amazon a constaté que son IA de tri pour les candidatures pénalisait les femmes car leur modèle contenait essentiellement des données de CV masculin.
De même, si l’IA rencontre une situation qu’elle n’a jamais vue dans ses données d’entraînement, elle ne saura pas quoi faire. C’est ce qui s’est passé avec un véhicule Uber autopiloté qui a tué un piéton qu’il n’a pas réussi à identifier car la personne se trouvait en dehors d’un passage pour piétons.
Pour rappel, si les captchas sont essentiellement axées sur ce qui se passe sur la route ; feux de circulations, passage piéton, bouches d’incendies, ponts, vélos, motos, bus, etc… c’est justement pour entrainer des modèles d’IA de conduite automatique à reconnaitre ces élements.
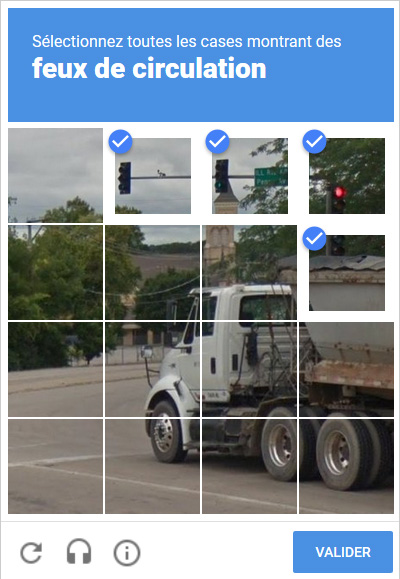
Cercle vicieux ou vertueux ?
L’intégration de l’IA dans un grand nombre de produits grand public entraînera une énorme pression pour collecter encore plus de données afin de l’entraîner toujours plus quitte à se passer de demander la permission.
Un exemple notable est celui de Clearview AI, qui a récupéré des images de personnes sur le web (merci les réseaux sociaux) et les a utilisées pour entraîner son IA de surveillance faciale sans l’autorisation des personnes concernées. Sa base de données contient environ 20 milliards d’images.
Clearview a fait l’objet de toutes sortes de poursuites, d’amendes et d’ordonnances de cessation d’activité en raison de son mépris flagrant pour la vie privée des gens. Elle a également eu à payer de nombreuses amendes (20 millions d’euros par la CNIL en France) et a résisté à la suppression des données malgré les ordres des régulateurs de nombreux pays.
Il faut surtout comprendre que plus nous utiliserons l’IA, plus les entreprises voudront collecter nos données personnelles afin de rendre, par exemple, notre -futur- assistant vocal plus prompt à nous comprendre et à nous influencer fournir des réponses plus pertinentes.
Au fur et à mesure que différentes Intelligences Artificielles seront appliquées à de nouvelles fonctions, elles se trouveront exposées à des informations de plus en plus sensibles.
Le problème est que l’omniprésence de l’IA pourrait rendre la collecte de données presque impossible à éviter.
OpenAI semble faire des efforts pour respecter la vie privée des utilisateurs de ChatGPT. Dans une récente mise à jour (10 mai 2023), l’entreprise a introduit la possibilité de désactiver l’historique de chat, ce qui signifie que les conversations débutées lorsque l’historique de chat est désactivé ne seront pas utilisées pour entraîner et améliorer leurs modèles. De plus, ils travaillent sur une nouvelle offre d’abonnement ChatGPT Business pour les professionnels et les entreprises, qui n’utilisera pas les données des utilisateurs finaux pour l’entraînement par défaut.
Ils ont également facilité l’exportation des données des utilisateurs pour une meilleure transparence. C’est un pas dans la bonne direction, mais est-ce vraiment suffisant ? Est-ce que cela change la donne ou est-ce simplement un moyen pour OpenAI de gagner notre confiance tout en continuant à collecter des données massives ?
Veuillez noter qu’une fois les données collectées, il est très facile de les utiliser à des fins auxquelles les gens n’ont jamais consenti puisque le principe repose sur la compilation d’informations. En effet, compartimenter celles-ci serait un problème au développement, l’efficacité et à la pertinence d’un IA.
Sécurité en ligne : Qui veille sur vos données personnelles en France ?
Pour conclure : Quel avenir pour la vie privée avec les IA ?
Déjà que notre navigation Internet n’a plus de secret pour grand monde, sauf, bien sûr, si vous utilisez un VPN (Réseau Privé Virtuel), la quantité globale de données collectées va monter en flèche à mesure que l’IA et les chatbots s’améliorent et sont utilisés.
L’Italie vient d’ailleurs d’interdir momentanément l’utilisation de chatGPT pour des préoccupations liées à la confidentialité des données et à l’absence de vérification de l’âge des utilisateurs, a conduit à une explosion des ventes chez les fournisseurs de VPN.
Si, pour le moment nous regardons tous OpenAI comme un outil fabuleux et j’ai surtout une pensée pour les étudiants qui s’en donnent à cœur joie. Ce n’est que le début. Nous percevons ChatGPT de la même façon que les premiers internautes percevaient l’Internet au début.
Actuellement, tout le monde s’inquiète un peu de la façon dont les grands groupes peuvent subtilement influencer nos prises de décision et créer des bulles de filtres presque impossibles à fuir sans l’aide d’une IA.
L’Intelligence Artificielle est un outil puissant qui pourrait conduire à toutes sortes de nouveaux développements, mais aussi beaucoup de dérives pour la vie privée de ses utilisateurs. La question de savoir s’il sera utilisé et développé de manière responsable reste en suspens.
Imaginez si un modèle d’IA était conçu et développé dans le but de contrôler la population ? Ça vous semble impensable à vous ? Et pourtant, on a déjà tous acheté quelque chose sur Internet en ayant été influencé par des algorithmes, qu’on l’assume ou pas.
Ce que nous percevions comme une menace lointaine est devenu une réalité quotidienne. Aujourd’hui, ce ne sont plus seulement les grandes plateformes qui collectent vos données, ce sont aussi les outils que vous utilisez vous-même pour travailler. Ce que vous confiez à un agent IA sans le savoir mérite d’être compris.








